 Figure 1
Figure 1Abstracts of SUSI posters and presentations
The abstracts are presented in an alphabetical order. Some are in English, some in Dutch. I have not edited the texts, but I have made the styles more or less uniform. At this moment some abstracts are still missing.
Raymond Veldhuis, 01/12/99
Butlers for Interactive Products with Speech control (BIPS)
Mathilde Bekker and Leo Vogten
IPO
Introduction
Nowadays interactive products offer more and more functionality to interact with technologically complex systems. This makes it difficult for users to understand all the ins and outs of a product. Providing an assistant in the form of a butler, users could be assisted in interacting with interactive products, thus making the products easier and more fun to use. The added benefit of a butler can be to provide a more tangible means of help to users, and also to provide shortcuts for the more complex tasks, that possibly have to be performed over a period of time. In contrast to a more "agent-like butler", the emphasis in the current project is intended to be on a more "valet-like butler", who is good in supporting the user, but is less inclined to take initiative.
In the MAMUt project exploratory research was conducted, in which the use of a butler as support for interacting with multiple appliances was examined and users controlled tv, video and audio equipment by means of Voice Command & Control operation. The butler also provided explicit feedback about the state of the applications and could be asked to carry out a combination of actions that were defined in one pre-set command. In this study the butler turned out to be helpful and highly appreciated by the users. Of course butlers can be useful for interacting with a single appliance. However, because of the increased complexity of interacting with multiple appliances, a butler might be even more useful in such a context of use.
Other butler design issues have to be tackled, if the design should support the interaction of the butler with multiple users. In that case, for example, the butler should be able to indicate to whose command it is reacting, and to which person it is listening.
Research questions related to the interactive butler are:
Technological questions:
Project description and main activities
The aim of the project is to examine the added benefit of a butler for a range of interactive products or systems. Furthermore, the influence of different ways of representing and interacting with the butler on the perceived benefit of the butler will be examined. After an initial literature study, two appliances will be selected (e.g. a butler for interacting with some appliances on a PC, or for interacting with hifi equipment) for which an interactive butler will be designed and implemented. Next studies will be conducted to examine relevant research questions. Finally, the butler(s) will be redesigned.
Relation with other (IPO) research projects:
Project: Formalized Content in USI
Tijn Borghuis, Herman Geuvers, Kees Hemerik, Rob Nederpelt, Martijn Oostdijk
Informatica
Introduction and Background
Ever since the Automath Project (late Sixties), research has been conducted at the faculty of mathematics and computer science into the use of type theory for the formalization of Mathematics and for
automated theorem proving. This research has shown how parts of mathematics and computer science can be completely formalized inside the type theoretical formalism, and subsequently be checked and
manipulated by means of computer programs. Over the last couple of years it has become clear that the ability to completely formalize content is not just of interest for doing formal mathematics: if we
take the formalized content to be the "domain of discourse" between the user and the system, new and interesting possibilities for User-System Interaction arise.
In Type Theory the semantics of the application domain (or content) of a system can be captured because of a particular advantage of this formalism: it allows the concise representation of domain information, including the dependencies between different pieces of information and the "justification" or "evidence" for the information. This is established using the notion of "context", a formal object representing the information.
With respect to USI, a crucial property of the formalization of information in a (formal) context is that the handling of the interaction can use the semantics of this information (captured by the context-representation). Although the examples used throughout this presentation will be for mathematics, a very wide range of domains can be formalized in this way. For instance, in the DenK-project the application domain was an electron microscope, the workings of which were formalized in type theory. In addition to these possibilities for structured representation of content, type theory offers a very strong system for (automated) reasoning about this content.
Formalized content
The structure of the formalized content can be exploited in several ways in USI.
(1) Presentation to the user.
One can present the user with different coherent "views" on the same piece of content. For instance, a user can view and edit a mathematical proof in both a graphical form (e.g. derivation tree) and a natural
language form (mathematical textbook style), switching at any time to view that is most convenient for his current purpose. In addition, the structure of the representation can be used to present information at
various levels of detail, allowing the user to selectively "unfold" and "fold" parts of the contents: more detail can be made visible if the user wants to inspect something more carefully, detail can be hidden by the user when he is not interested. These various levels make sense to the user, because they are derived from the structure of the content itself.
(2) Studying and extending the content.
The reasoning facilities offered by type theory allow the user to obtain new information about the domain, either by interacting with the system (e.g. as in constructing a proof for a mathematical theorem) or by querying the system. Because of the presence of the justifications, any information that is derived by the system will come with its own compound justification, consisting of all the justifications of the information that was used to derive the new conclusion along with the way they were combined. This seemingly
highly abstract property has an important consequence: the system can provide the user with reasons, i.e. it answers "Why-questions".
(3) User modeling.
The representation technique described above can not only be used to formalize the domain, but also to capture the user's current knowledge of the domain. By involving this simple user model in its reasoning
about the domain, the system can tailor its response to queries to the user's familiarity with the domain at the given time.
It will be clear, that the aforementioned possibilities of using fully formalized content become of interest only when the application domain is complex and structured, and when the user needs to interact with
this domain in a relatively unrestricted way. To make this more tangible, we will present (including a demo) a project which is at the heart of our current research into formalized content for USI: "Interactive Books, Presentations of Formal Proofs". The domain of this project is mathematics, in particular it deals with interactive books on mathematics and computer science. We are in the stage of developing a tool that can present formalized mathematical content in a flexible way (making use of the semantics of the content) to the user. This covers (1) above. The formalized content itself is not generated by the tool, but by an (interactive) theory development system. With this first implementation, we want to exploit options (2)
and (3) mentioned above. This should allow the possibility of generating formal content interactively with the tool.
Questions
The main question that arises here is of course whether all this can really work in such a (flexible) way that users will see the advantages of it (and actually want to use it). We have too little knowledge on general user interaction and user modeling to have a good picture upon this. In general, we think that, to make our approach really work, we will need to combine it with (aspects of) other USI systems, e.g. to obtain a good reactive behavior. We have evidence (the DenK project) that our approach of `formalizing content in a formal context' may be applicable more widely, but we would like to see more possible applications. What are other situations where user interaction may profit from the fact that the semantics of the content is formalized?
ToKen2000: Toegankelijkheid en Kennisontsluiting op de elektronische snelweg.
Don Bouwhuis
IPO
Token2000 is een onderzoekprogramma in het kader van het Nationaal Actieplan Elektronische Snelwegen, dat een initiatief is vaan een groot aantal Nederlandse Ministeries bedoeld om het maatschappelijk draagvlak en de technische infrastructuur van de digitale snelweg in Nederland te optimaliseren. Als kernpunten worden daarbij gezien de toegankelijkheid van informatie op die snelweg voor een zo groot mogelijke groep van individuele burgers, en de ontsluiting van die kennis op zodanige wijze dat de beschikbaarheid en benutbaarheid zo groot mogelijk wordt. Vanuit een dergelijk perspectief ligt een samenwerking tussen Cognitiewetenschappen en Informatica voor de hand, die in feite al was aangegeven in de Rapportage van de Overlegcommissies Wetenschapsverkenningen van beide disciplines. Het project bestaat uit twee fases, een eerste, verkennende fase waarin de raakpunten van Cognitie en Informatica op dit gebied wordt geïdentificeerd en geconsolideerd, en een onderzoekfase waarin langer lopende projecten voor postdocs en aio's kunnen worden uitgevoerd.
Het programma, uit hoofde van de maatschappelijke betrokkenheid van de overheid, is gericht op drie toepassingsgebieden: het Culturele Erfgoed en onderwijs, de Zorgsector en Politie en Justitie.
Bij het Culturele erfgoed gaat het om het ontsluiten van bestanden met cultuurhistorische gegevens en deze via intuïtieve en aansprekend interfaces ter beschikking te stellen aan een gevarieerd publiek van belangstellenden en deskundigen. Dit toepassingsgebied is gekozen als onderwerp voor de eerste verkennende fase, en het bestand van het kunstbezit van het Rijksmuseum is het specifieke voorwerp van onderzoek.
In de Zorgsector gaat het, wat gebruikersinteractie aangaat vooral om gebruiksvriendelijkheid, die een belangrijke rol speelt bij vaak vertrouwelijke documenten zoals bijvoorbeeld bij het EPD (Elektronisch Patiënten Dossier). Daarnaast hebben cliënten van de zorgsector baat bij een gebruiksvriendelijke toegang tot voor hun relevante informatie, maar anderzijds hebben de professionele zorgverleners als regel behoefte aan toegankelijkheid en ontsluiting van veelal ergens gecentraliseerde informatie die moet worden opgewerkt tot bruikbare informatie voor de cliënt.
Bij Politie en Justitie spelen vooral beheersprogramma's voor bedrijfsprocessen een rol. Niet alleen gelden strenge normen voor vertrouwelijkheid, vaak moet ook worden afgegaan op incomplete en vage informatie, gegevens moeten vaak onder stressvolle omstandigheden worden ingevoerd, er kan sprake zijn van grensoverschrijdende gebeurtenissen en netwerken moeten snel en compatibel zijn. Bij justitieel onderzoek is automatische taalbewerking van dossiers om diverse redenen zeer gewenst, maar schiet nog tekort op de kracht van die analysemethoden en de gebruiksvriendelijkheid van de bijbehorende programma's.
In de verkennende fase werken zes instituten in Nederland; drie op cognitief en drie op informatica gebied, samen op de ontwikkeling van een interface voor het raadplegen van het kunstbezit van het Rijksmuseum. In Eindhoven zijn dat het IPO en Tema van de TUE. Het Build-It systeem zal hierin een centrale rol spelen, en het is de bedoeling dat het objectenbestand van het Rijksmuseum op elk van de deelnemende instituten beschikbaar komt.
On the survey design of probability questions: Fifty-fifty = 50%?
Wändi Bruine de Bruin
Technology Management
Background
Many risk perception and product evaluation surveys have used probability questions, asking respondents to use probabilities to describe degrees of uncertainty, risk, and confidence they experienced. A basic understanding of probabilities is essential if people are to communicate their (probabilistic) beliefs to one another, and to researchers conducting surveys that include probability questions. Miscommunications may arise when people use of "50" as a proxy for the verbal phrase "fifty-fifty chance", without intending the associated number of 50%. One sign of this tendency can be seen in the seemingly excessive use of the "50" response in many studies of risk perceptions (in which respondents are asked to assess the probability of various adverse events in such areas as health, crime, weather, and environmental issues). This exaggerated use of "50" leads to seeming overestimations of small probabilities, and unwarranted research conclusions that may possibly have serious consequences.
Research questions
This presentation addresses (1) What determines the prevalence of saying "fifty-fifty"?; (2) How can survey designers prevent the emergence of a "50 blip" in their data?; (3) What can be done about "50 blips" in existing data? I will present the results from paper-and-pencil experiments, in which respondents from different backgrounds answered a wide variety of probability questions.
Results
First, several determinants of the rate of using "50" will be identified, including conditions evoking (a) verbal (rather than numeric) thinking, encouraging the availability of the verbal phrase "fifty-fifty chance", and (b) epistemic uncertainty, or not knowing what number to use. My results provide insight into the fundamental cognitive processes involved in assessing probabilities.
Second, practical implications will be discussed. These include a list of easy-to-implement survey design strategies researchers can follow to reduce the use of "fifty-fifty" in their studies.
Finally, I will suggest methods to diagnose the unwarranted use of "50" in existing datasets, and to correct for their excessive use. A Carnegie Mellon study (conducted at the Department of Engineering and Public Policy) asking a sample of American engineers to answer open-ended probability questions about their own field (i.e., remediation of ground water pollution) will be used as an example. Surprisingly, these experts also showed an excessive use of "50".
Public Health Engineering (PHE) for the Built Environment
Prof. Annelies (J.E.M.H.) van Bronswijk PhD Biologist (TUE), Cor E.E. Pernot MSc Physicist (TNO), Wiet (L.G.H.) Koren PhD Chemist
Aim
Elucidating the principles underlying a built environment that supports the health of its users and makes healthy behaviour of users self-evident, without taking away their freedom of choice or independence.
Elucidating the principles underlying a built environment that supports the health of its users and makes healthy behaviour of users self-evident, without taking away their freedom of choice or independence.
Domain
Let's transform 'My home is my castle' in 'My home is a friend'. PHE answers grave societal problems, such as the needed reduction of the growth of cost of care for the growing number of older persons, who will constitute 1/4 of the population by 2015.
From the origin of mankind the built environment has protected users against the evils of the physical outdoors: storm, rain, too much sun, predatory beasts and quarrelling humans. In doing so it also created a new environment with its own risks.
Modern PHE uses Building Engineering and Urban Design to prevent infectious disease (pneumonia, gastero-enteritis), allergies, chronic bronchitis, accidental falls, cancer, chronic stress, while taking special notice of the sensitiveness of older persons and small children for these diseases. In addition PHE thrives towards additional building services, such as promoting health by installing bio-feedback in addition to managing environmental parameters.
PHE for the 21st century uses data from different and diverse sources. User interfaces need to be exceptionally consumer-friendly. This will make mass individualisation possible, also to the point that the built environment becomes tailored to the needs and ambitions of individual users.
Leading principles
European scale. The program includes geographical, climatic and cultural (building code) variation within Europe.
Health Classification of Buildings. A locally adaptive classification based on compression of current and expected morbidity, but translated into the technical terminology of building engineering and urban design, is the vehicle of knowledge towards applications in modern PHE (new building services).
Smart Built Environment. The new built environment is adaptive and adaptable to its users to assure safe water systems, low-risk indoor air or outdoor environment, and to supply health promoting bio-feedback, while respecting choices made by the users, and leaving them masters of the technology used.
Projects
Different aspects of the building environment influence morbidity and the number of healthy years in a life span. Basically a project consists of a cluster of MSc theses. Design of the optimal user-interface is a problem in each project.
Below is a preliminary list of projects in the program from 2000-2004.
Main activities
Activities in the program include:
Only in the last case will a procedure through the medico-ethical committee be necessary
Expertise wanted
As to user-system interfaces we need 2-4 designers who together specify and build a generic interface for all building services mentioned.
Product-Integrated Eco-Feedback
Dr. Teddy McCalley, Project Manager, ir. Peter de Vries, Research Assistent
Technology Management
Abstract
Governmental demands for environmentally friendly consumer products has encouraged the use of computer based systems in household appliances. These systems are able to enhance energy conservation from the product side yet much energy is still wasted from the user side. By focusing on the interaction between the product and the user it is possible to generate responsible conservation behavior using eco-feedback. Eco-feedback is information presented during the product-user interaction which prompts the user to adopt energy saving strategies, however, little is known about how such feedback works and thus how it can best be applied for optimal effect.
Theoretical principles support the expectation that product-integrated feedback can create and/or support increased conservation behavior in the user. The primary goal of the project 'Interactive Eco-feedback' is to identify the relevant fundamental principles governing human action and performance in response to immediate feedback regarding energy consequences of washing choices. The exploration and testing of various forms of feedback embedded in the interface of a washing machine has yielded information that can be generalized to other household appliances. The research presented will focus on the importance of seeing feedback as only one part of an interactive relationship with goals and behavioral options and how that relationship must be tailored to various user groups.
Video-based Interaction Platform and User-Centred Design
Paul de Greef
IPO
In user-centred design (UCD), application development, and even hardware development, is to be steered by the user's goals, knowledge and capacities. An application ideally should make it simple for the user to reach his goals. For that purpose, the application and the interaction style should not assume knowledge or capacities users do not possess and, to avoid high cognitive load, the application should provide a minimally sufficient set of functions to achieve the users' goals.
Video cameras and LCD projectors enable a novel kind of human-computer interaction. The image that is shown on a PC's monitor can be projected to an ordinary table top. Users can sit around the table and a video camera can watch their behaviour and partly replace mice and keyboards. The IPO has such a Video-based Interaction Platform (BuildIt™) that uses an infra-red camera and infra-red reflecting blocks (bricks) for two-handed user input (Rauterberg, 1997, Fjeld et al. 1999).
This video-based interaction style is extremely easy to learn and use, as confirmed in two projects at the IPO and this is sufficient motivation to further explore and develop video-based interaction. The development process can be steered by user-centred design, with application-development projects as empirical basis, and 'multiplied' across applications by development and improvement of a common user-interface software architecture.
Although it is to be expected that other modalities such as speech input need to be added, the proposed approach for development is to stay close to the original interaction concept, and to add interaction operations or other modalities on an if-needed basis only. Development in real applications and having real users as participants in empirical evaluations is essential to avoid developing 'solutions' without knowing the 'problems'.
An example of UCD development
The TEAroom project addresses tele-applications for image viewing. We started from a simple medical image viewing application intended for doctors sitting around the same table. The functionality of this application is limited to selecting one or few images for viewing (and comparing) in the large. This system was extended to a mock-up tele-application distributed over two adjacent rooms. In experiments with users it appears that users in a quite natural way use their finger to point out details in images (see Figure 1). This works well when two users sit at the same table, but in the distributed version the other person cannot see it. This leads to extending the tele-application to support finger pointing.
Figure 1
An example of improving the user interface architecture
Figure 2 shows the current architecture of VIP. When the user selects an image by placing a brick on a thumbnail picture to the left, the image is shown in the large to the right. Like in a GUI for a desktop PC, the user may appreciate visual feedback when a thumbnail is selected. Currently this is the responsibility of the application and in ours, the application draws a red rectangle around a selected thumbnail. A next step would be to introduce an intermediate user-interface layer, and have this layer add a red rectangle to the image produced by the application.
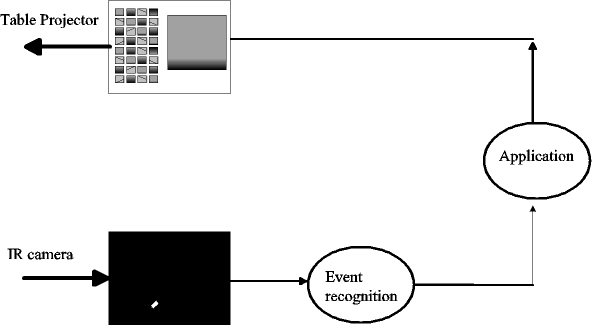 Figure 2
Figure 2
Projects
Current projects: SIMS: medical images, TEAroom: PhotoShare tele-application, ToKeN2000: experimenteerplatform electronische snelweg , AIO project A. Malchanov.
Non-speech audio for user interfaces
Hermes, D.J
IPO
Abstract
In het project "non-speech audio for user interfaces" wordt de rol van geluid onderzocht in mens-systeem interactie. We concentreren ons hierbij op digitale, virtuele systemen zoals een computerprogramma. De meeste van deze systemen gebruiken geluid hoogstens als waarschuwingssignaal. Er zal eerst worden aangegeven waarom geluid maar weinig in virtuele systemen gebruikt wordt. Dan zal aangegeven worden aan wat voor voorwaarden geluid moet voldoen, voordat het op bevredigende manier in mens-systeem interactie aangewend kan worden. Voordat er aan deze voorwaarden voldaan kan worden, moet er onder meer onderzoek verricht worden op het gebied van sound design, real-time synthese van geluid, collocatie en synchroniciteit tussen beeld en geluid, natuurlijkheid van geluid, auditieve objectperceptie, en acceptabiliteit van geluid.
(Semi-)automatic generation of hypermedia presentations for volatile database information
dr.ir. Geert-Jan Houben, prof.dr. Paul De Bra
Informatica
Main subject and goal
The presentation of information retrieved from a traditional (relational) database can be improved (from a user's point of view) by offering a hypermedia presentation. The generation of such a hypermedia presentation usually requires a significant effort from a human designer. For ad-hoc (unforeseen) queries on this information it is not feasible to manually generate a hypermedia presentation. The goal of this project is to develop a system that facilitates the (semi-)automatic generation of hypermedia presentations for ad-hoc (volatile) queries on relational data. Prime application areas are electronic program guides, real-estate databases and mail-order catalogs.
Project description
In WIS (Web-based Information Systems) the transformation of information retrieved from different data sources to presentations suitable for different kinds of viewing is a crucial element. This project has started with an early goal to obtain insight in the process of automatically generating hypermedia presentation for legacy relational data. Motivated by specific application types, such as real-estate databases, mail-order catalogs and electronic program guides, the goal was to add value to the existing (relational database) application by offering the possibility of obtaining a hypermedia version of a query result. Thus, for example, it could become possible for data stored in a relational database to view an ad-hoc query result with a Web browser.
While in general the generation of a hypermedia presentation for query results is a process that involves several kinds of (human) expertise, we focused on ad-hoc (volatile) queries. Assuming that for the standard queries hypermedia presentations can be specified beforehand, the main question in this project is how to handle the ad-hoc and unforeseen queries. Obtaining a pragmatic solution for this design process is the goal of this project. One aspect is the use of heuristics that represent rules how to derive a hypermedia presentation based on a query specification.
In the entire automatic generation process of getting from the source data to a "suitable" presentation several aspects are important:
These aspects represent different kinds of adaptation of the information: while the query "simply" asks for some data, the different aspects play a role in the generation process. These aspects become even more important after the choice to consider multimedia presentations (instead of hypermedia presentations).
Obtaining an insight into the fundamental aspects involved in the generation process of multimedia presentations for relational data has thus become the formal goal of this project.
Multi-modal Interaction Research: present and future
A.J.M. Houtsma
IPO
Summary
The research program Multimodal Interaction at IPO currently focuses on the development and transfer of fundamental knowledge about modality selection and adaptation to support the design process of interactive systems. With respect to user input, this has led to research activities in the area of human perception (vision, hearing, touch, kinesthesia), particularly combinations of these sensory modalities, and to the exploration and development of complex, multimodal system displays. Examples are a recognizability study of physical attributes of a sound source (material, velocity, hardness) from a sound, or a study of human tolerances for asynchrony between a simultaneous visual and auditory display of a common source. With respect to user output, current research focuses on performance in motor tasks like target acquisition with mouse, joystick or trackball control, with or without force feedback.
One common feature in all studies undertaken so far is that experimental paradigms always are computer-simulated or laboratory-generated abstractions of things we encounter in every-day life. This has the advantage of having a potentially well-controlled environment in which variables can be systematically manipulated, so that experimental results can be unambiguously interpreted. Nevertheless is sometimes very useful to augment such formal, systematic efforts with a thorough analysis of a complex user-system interaction process taken directly from the real world. For instance, an analytic study of the TADOMA speech communication method (taught and used in the USA to let deaf-blind people 'feel' the speech signal directly from the face of the speaker), done at MIT in the late 1970s, turned out of great relevance for the many engineering efforts that had been put into the development of effective vibro-tactile speech displays. The study not only set a benchmark for human perceptual limits of vibro-tactile speech coding, it also showed that the principal reason for failure of most artificial displays was the lack of time that users were given to adapt to such displays.
A very intensive, multimodal human-system interaction process taken from daily life is reading and playing music. When we play sheet music on a violin, our perceptual system is busy reading the notes, while our auditory and tactual senses (and for beginners also the visual sense) are occupied absorbing crucial feedback information from the instrument. Our cognitive system is busy recognizing and interpreting patterns in the notes that are read, and generating the proper input commands for our motor system that takes the (playing) action. All elements of the perception-cognition-action triangle are present, with the additional advantage that, in principle, we have a complex multimodal interaction process to which the human user (expert musician) is fully adapted. Through electronic simulation of instruments it is possible to selectively manipulate any of the feedback loops or elements of the music score display, in order to gain insight in the relative contributions of the various components of the interaction process, both in a qualitative and a quantitative manner. It is anticipated that such knowledge is useful for understanding many other, non music-related interactive processes.
Target acquisition with visual and tactile feedback
A.J.M. Houtsma and H. Keuning
IPO
Summary
This research project deals with the problem of target acquisition when using a graphical computer interface. A situation typical for present computer technology is that a computer user moves a cursor from some arbitrary position to an intended target, which is visually displayed on a CRT screen, by means of some hand-held control device like a mouse. Visual feedback is in such a case the only controlling factor that can make the cursor reach the target. Tactile feedback from the control device provides only local information about that device, and says nothing about where the cursor or the intended target are.
Some recently developed manual control devices (e.g. the Feel-it Mouse, the Virtual Reality Mouse, or the Trackball with Force Feedback) allow the user to receive active tactile information about the acquisition process from the computer. Such tactile information is likely to help the user find the target, provided that it is consistent with the visual information.
The project will be executed with two mechanically different types of input devices, a mouse and a trackball, and consists of four phases. In the first phase an attempt will be made to describe general (cursor) movement as a function of direction and control device. Paths may not necessarily be linear but rather curvilinear because of the physiology of fingers, wrist and arm. In the second phase a detection algorithm will be developed that estimates, from an as short as possible measured initial path, which target (out of multiple potential targets) the user is moving to. The third phase concerns the determination of the optimal feedback force field to be applied once the intended target has been determined. The fourth and final phase will consist of the evaluation of the performance of such an adaptive force feedback system in comparison with a traditional visual-feedback-only control system.
ImMediaTE - Immersive Media for Televised Events
Wijnand IJsselsteijn
IPO
Aim
The aim of the current project is to develop and evaluate a multisensory, immersive TV system that will evoke the sensations and emotions of attending a live event in a home viewing environment.
Relevance
Being present at a live event is undeniably the most exciting way to experience any entertainment. This is true whether we are talking about a musical concert, a theatrical performance, a soccer match, or even a firework display. The ability to direct your gaze where you wish, to hear sounds from all around you, to experience the immediacy and expectation of an unscripted happening, to feel the buzz of the crowd and to smell the grass or smoke, are all sensory cues which contribute to the powerful experience of being there, also known as presence. Cinema has over the decades experimented with the technology necessary to encourage presence, such as widescreen (to fill the viewer's visual field), stereoscopy (to mimic human vision) and multi-channel audio (to reproduce directionality). However, current broadcast TV formats do not support such a multisensory, immersive experience yet, although much of the technology is currently available. The ImMediaTE project will attempt to develop an integrated multimodal display platform called immersive television, that will combine wide-angle HD views of live events with multichannel (directional) audio, motion feedback (e.g. via a low cost motion platform), olfactory and tactile (e.g. wind) stimulation. A significant feature here, however, is that this platform will need to be developed within broadcast constraints (i.e. one-to-many distribution), which will necessarily define the cost and bandwidth of the system. The format will aim to provide a (limited) amount of interactivity because each viewer's behaviour can be supported through interaction with the home terminal (i.e. the set-top box). Figure 1 is an illustration of how such interactivity may be envisaged , using a head-mounted 'look-around' display. Other display formats are also being considered.
Background
Much of the research on immersion and presence has been concentrated in the domain of virtual reality (VR) which is well suited to producing immersive experiences for training, computer-aided design and games applications. As a broadcast entertainment medium, however, VR has severe limitations: the quality of computer-generated imagery will for very many years be inadequate to convince a user that he is actually viewing real-world scenes, there is no mechanism for capturing large-scale live events and rendering them in real-time, and VR is a highly interactive technology requiring individual processors for each user and wideband interactive networks (Lodge, 1999). Immersive television aims to overcome these restrictions and to provide an exciting new broadcast medium.
When a viewer is presented with a high fidelity reproduction of the physical world a compelling sensation of "being in" the depicted scene can be elicited. This sensation is termed presence, defined as a sense of "being there" in a displayed scene or environment (Barfield, Zeltzer, Sheridan, & Slater, 1995). Broadcast systems already developed, or currently under development, include high definition video and audio transmissions (Slamin, 1998), stereoscopic television services (e.g. Pastoor, 1991, 1993; Motoki, Isono, & Yuyama, 1995) and display systems with larger fields of view (e.g., Hatada, Sakata, & Kusaka, 1980), digital surround sound and improved image quality. These improvements can be viewed as attempts to increase realism by increasing the size and fidelity of displays, with corresponding effects on the impact, and observers' subjective appreciation, of the displayed material (Pastoor, 1993; Yano & Yuyama, 1991; Motoki, Isono, & Yuyama, 1995).
Viewers of such advanced broadcast services receive more sensory information characteristic of reality than from moving flat pictures of conventional TV resolution and size. We have previously shown, during the EC-funded ACTS TAPESTRIES project (1996-1999), that the presentation of additional sensory information, in terms of stereoscopic or motion parallax cues to depth, can enhance viewers' sensations of presence, particularly when the stereoscopic depth was presented using natural (non-exaggerated) disparities (IJsselsteijn, de Ridder, Hamberg, Bouwhuis, & Freeman, 1998; Freeman, Avons, Pearson, & IJsselsteijn, 1999). ImMediaTE may be viewed as a logical extension of Workpackage 2 of the ACTS TAPESTRIES project, building on expertise in presence evaluation in order to create viewers' presence through a multisensory, immersive experience. Much of the work performed under TAPESTRIES WP2 was aimed at developing reliable means of measuring presence. This will again be a topic of central importance in ImMediaTE, since the outcome of several stages of evaluation will inform the design of subsequent prototypes, up until the end of the project, when the final demonstrator system will be tested. New presence measurement methodologies will also be explored, in particular those that will be sensitive to the unconcious, automatic responses of observers that may accompany a sense of presence (e.g. postural movements, galvanic skin response). The IPO, Center for User-System Interaction will have substantial input in both the design and evaluation of the immersive TV system.
What makes a good Interface?
T.J.W.M. Janssen & F.J.J. Blommaert
Aim
Relevance
Typically, the design process of an interface is a cyclic procedure in which prototypes are developed, evaluated, improved, and re-evaluated. Three types of knowledge are required in this process. The first type of knowledge is generic knowledge of the user-system interaction process. This type of knowledge is mostly implementation-independent knowledge about the requirements which must be imposed on an interface in order for it to support satisfactory user-system interaction. The second type of knowledge is platform-specific knowledge of implementation techniques, that is, knowledge about how to implement an interface given certain combinations of hardware and software. The third type of knowledge is knowledge about procedures and techniques to evaluate a given implementation of an interface, including knowledge about how to translate the evaluation results into recommendations for improving the interface.
The current state-of-the-art at IPO is that significant amounts of all three types of knowledge are lacking. For present and future design processes to be nevertheless successful, an important research effort must be spent on reducing the existing knowledge gaps. We feel that in doing this, a balance must be found between the amounts of effort spent on increasing generic, design, and evaluation knowledge. In our view, the generic knowledge presently available at IPO consists primarily of fragmented knowledge about certain aspects of user-system interaction, which hampers the successful application of generic knowledge in the design process. To improve this situation, we feel that more effort should be spent on integrating and extending IPO's generic knowledge.
This, however, is not the only reason why we feel generic knowledge at IPO should be improved. First, generic, design, and evaluation knowledge are not as independent as perhaps suggested above. Generic and evaluation knowledge, in particular, are strongly related. An evaluation can only be adequately performed when it is known which processes play a role in user-system interaction and what requirements these processes impose on the interface. Conversely, knowledge obtained in the evaluation process can be used to test and to further develop generic knowledge. This interdependency again suggests that a balance between the different types of knowledge is necessary to optimise the chance of success in the design process. Second, developments in interface technology have so far been primarily technology-driven due to lack of knowledge about the user. Improved generic knowledge offers the opportunity to guide these developments, stimulating a less technology-driven and more user-driven approach.
Approach
Quality refers to the degree to which imposed requirements are satisfied (Janssen, 1999). The term interface quality thus refers to the degree to which an interface satisfies the requirements which are imposed on it. The conclusion from this must be that, to design a good interface, we must know which requirements are imposed on it and how to satisfy these requirements. An answer to this research question constitutes the core of generic knowledge about interface quality.
Exactly what requirements are imposed on an interface follows from the user-system interaction process, in particular from the user's goals within this process. When we regard the user-system interaction process as a kind of goal-directed dialogue between the user and the system, the interface assumes the role of a medium for this dialogue. Since the aim of the user is to successfully attain his goals, the quality of the interface may be regarded as the degree to which the interface supports the user in successfully attaining his goals through this dialogue. To understand what 'successfully' means in this context, we need to investigate the characteristics of the human interacting with his environment.
Following Newell & Simon (1972) and Newell (1990), we regard humans as highly developed information-processing systems of limited speed and capacity, capable of attending to multiple goals, and functioning in a complex and dynamic environment. Furthermore, to study the human information-processing system we choose to adopt a computational approach. Within this approach a distinction is often made between three levels at which an information-processing system can be understood (Marr, 1982). These levels are the level of the computational theory, the level of the algorithm, and the level of the physical implementation. An important advantage of making this distinction is that a description of an information-processing system at all three levels makes explicit (1) the goal of the information-processing task being performed, and the strategy which is followed to complete it, (2) the boundary conditions resulting from the hardware in which the system is implemented, and (3) the specifics of an algorithm which, given the boundary conditions of the hardware implementation, is able to perform the information-processing task. In other words, it makes explicit what the system is supposed to do, and how the system may be doing this given the limits of its physical implementation.
At a very general level, the primary boundary conditions resulting from the physical implementation of the human information processing system are limits on the available capacity which can be used to perform information-processing tasks, and limits on the speed with which these tasks can be performed. Therefore, since the system has to attend to multiple goals, only limited time and resources can be used to attain a certain goal. To deal with this situation, the system may rely on three mechanisms (Simon, 1967; Simon, 1990): (1) the use of approximate methods (heuristics) to guide the process of attaining a desired goal, with the aim to reduce the amount of time and effort needed to attain this goal, (2) termination of a process attaining a desired goal when a goal has been attained which qualifies as satisficing, or 'good enough', and (3) management of multiple goals, prioritising some goals relative to others according to what the current situation requires and according to the progress being made towards the respective goals.
If we consider the first and second of the above mechanisms, we may express the degree of success with which a 'satisficing' goal has been attained in terms of two factors. The first, effectivity, refers to the degree to which the goal currently attained corresponds to the desired goal. The second, efficiency, refers to the ease with which this goal was attained. Effectivity and efficiency may both be expressed in terms of a penalty; for effectivity this penalty may be expressed in terms of a 'distance' between the goal currently attained and the goal which is desired, while for efficiency it may be expressed in terms of the amount of time and effort needed to attain the current goal. For the degree of success with which a satisficing goal is attained both effectivity and efficiency play a role, weighing in differently according to the willingness to invest effort into minimising the distance to the desired goal. In general, the lower the weighted sum of their penalty terms, the bigger the degree of success.
Returning to the above three mechanisms, it is widely believed that emotions play an important role in the third mechanism (Oatley & Jenkins, 1996). According to this view, emotions are linked to the perceived advancement of goals, being positive when the goal is advanced and negative when it is impeded or frustrated. Furthermore, positive emotions tend to prioritise the process attaining the current goal, whereas negative emotions tend to interrupt it. Considering our description of degree of success, we may have found an interesting interpretation of user satisfaction here: user satisfaction is an emotion which signals the degree of success with which goals and subgoals in the interaction are being attained.
Concluding, the description of interface quality which we have found here is in terms of the degree to which the interface supports user-system interaction which is both effective and efficient, and hence successful. At this point, the concept is still immature and it must therefore be further developed. Moreover, to quantify interface quality two important steps must still be completed. The first of these steps is the development of a metric for the effectivity and efficiency of user-system interaction. The second step is a parametrisation of the interface, such that the interface can be described in terms of a set of characteristics on the basis of which effectivity and efficiency can be quantified. Especially this second step may not be easily feasible, and it may be necessary to narrow down the scope of this research to a small and relatively well-defined case-study in order to complete this step.
Literature
A Data-Driven Approach to Talking Heads
Emiel Krahmer and Raymond Veldhuis
IPO
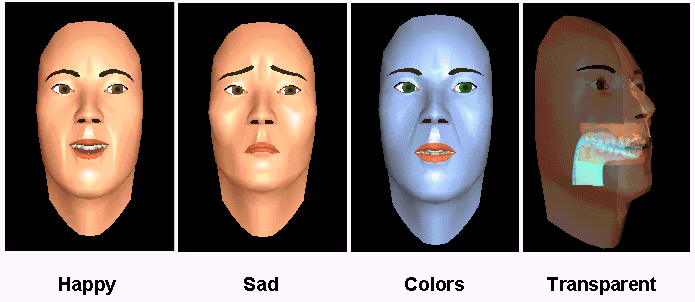
Relevance
Intelligibility of synthetic speech is sub-optimal in noisy conditions. Various experiments have shown that visual information can improve intelligibility under these conditions. This is already the case for the display of a moving pair of lips. However, the best results are obtained with a "talking head": display of the whole face renders the best understanding. Additionally, a talking head has various other beneficial properties: for instance, it can help manage turn-taking in dialogue, it can indicate processing of the underlying system ("thinking") and it can even suggest a kind of personality for the system. This personality partly resides in non-verbal communcation (e.g., raising an eye-brow to stress important information) and partly in the additional possibility of expressing emotions (see the happy/sad examples above). It is thought that sophisticated "talking heads" are beneficial both for the public acceptance of speech interfaces as well as for people with a hearing disorder. Possible applications are agents and avatars in dialogue systems, speech and language training for deaf children, and video phones, to name but a few.
Although some labs have shown convincing demos of talking heads, e.g. KTH (Per, August, et al), MIT (MikeTalk), UCSC (Baldi, see picture above), ICP and ATR, the field is still relatively new. Many of the existing systems are based on some form of mapping between phonemes and mouth positions (visemes). Such audio-visual synthesis does not reflect the coarticulatory process in which the realisation of both a phoneme and a viseme depend strongly on surrounding phonemes and visemes. As a result, the talking head gives the impression that there is a mismatch between the synthetic sound and the lip movements.
The discussion above might create the incorrect impression that 'ordinary' (non-visual) speech synthesis is a solved problem. Many of these systems are based on the concatenation of very small units such as diphones (diphones are small units excised from recorded speech, containing the transition between two phonemes). While this makes these systems highly flexible, the generated speech contains concatenation artefacts which partly explain the perceived unnaturallness of synthetic speech.
Project
In the proposed project, a solution to the problems with audio and visual speech will be sought by collecting a large database of audio-visual speech. Using this database, a speech synthesis system will be developed based on the concatenation of segments of variable length (and typically these segments may be longer than diphones, e.g., of syllable- or even word-length). This method, called unit selection, is less prone to concatenation artefacts, mainly because there is far less to concatenate. In addition, co-articulation is less of a problem since it is simply there in the units. Notice incidentally, that the system remains as flexible as desired, since the possibility to select small units is still available. In 2000, IPO will start with the development of a speech synthesis system for Dutch, based on unit selection, in close cooperation with ATR (Japan) and KPN Research.
It seems highly attractive to apply the basic idea of unit selection in the audio-visual domain. For this to work, we immediately build an audio-visual database by filming the designated speaker. After processing the data thus obtained, we have a database in which there is a one-to-one mapping between audio and visual units. This means that in the visual domain we are not forced to combine a set of static visemes, but rather have the opportunity to concatenate stretches of dynamic facial movements accompanying the relevant segments in the auditory domain. There is reason to expect that the resulting talking head will be perceived as more natural since the units are longer and thus the visual coarticulation effects are implicitly present in the units. Similarly longer units imply a closer match between audio and visual speech.
Probably, the easiest way to construct a talking head is by simply concatenating "facial" units in tandem with the concatenation of speech units, where more or less standard morphing techniques can be used to smoothen the visual breaks between segments. This is essentially the approach taken for MikeTalk, with the crucial difference that MikeTalk is based on only 16 static, 'facial' visemes/pictures. While this method makes it possible to develop a 'photo-realistic' talking face, it has also a number of disadvantages. In particular, it does not seem possible to generalize the method to include such ingredients of visual speech as eye blinks, eye-gaze changes, brow movements etc. Therefore, ultimately, we want to shift to real 'modelling' of the talking head. It is well-known that to model a face realistically, a multitude of parameter settings have to be continuously updated. Here the presence of a large database pays off as well, because many of the relevant parameter values can be estimated from the audio-visual data in the corpus.
Collaboration
IPO has a long tradition in speech research (in particular, prosody and speech synthesis). However, to make a success of this project cooperation with Electrical Engineering and Computer Science seems essential. Electrical Engineering (in particular, (visual) signal processing and pattern recognition) is a sine qua non for estimating the relevant parameters within the face. (It should be noted that while in general it is still a relatively difficult task to track, say, the mouth in a random face, the task here is easier in that during audio-visual data collection the face will be dressed up with approximately 30 fixed markers which may serve as anchoring points for the pattern recognition algorithms.) Computer Science (in particular, computer graphics) is vital for the real-time generation of the ultimate talking head.
Pen-based input for designers: drawing electronic schemes
Jean-Bernard Martens
IPO
The proposed project is within the framework of an investigation of different aspects of pen input, free style drawing and handwritten recognition and the incorporation of obtained results in designer applications. The development of a preprocessing system for SPICE (i.e., a well-known software package for electronic circuit simulation) based on free style drawing will be of special interest.
Pen-based input is not restricted to only handwriting. Another use of pen input is for graphical pattern input, or more concretely for free style drawing. Effective processing of free style drawings demands a multilevel recognition process.
Low-level recognition of free style drawings implies recognition of pen-drawn geometric shapes, which connects free style drawings with concrete geometric patterns like ellipses, circles, lines, rectangles and so on. We can see the similarity of this sort of recognition to on-line handwriting recognition and we can expect that experience worked out for on-line recognition would be very useful for geometric shape recognition in free style drawings. We would like to point out that in contrast to a very diverse offering of commercial products for handwriting recognition, the commercial offering for shape recognition of free style drawings is almost non-existent. This situation has probably arisen because alternative uses of pen input are only beginning to be explored. Historically, pen input for computers appeared as a replacement for keyboard and mouse and the efforts of developers were concentrated on alternatives for these device functions and not to optimally use the specific properties of the pen input. The only existing software package for pen-drawn shape recognition known to us is ShapeChecer, a product of ParaGraph Pen Technologies. Unfortunately ShapeChecker is not available as a licensable product at this moment and can only can be evaluated in a demo application. There are commercial offerings of software for geometric recognition on raster objects (for example, see http://www.audre.com), aimed at converting drawings and maps into graphical formats. In spite of the fact that these products offer numerous features and capabilities, they can not be utilized for pen input.
The second step in recognizing free-style drawings is understanding the geometrical relationships between elements, called the configuration recognition. This for instance includes deciding if basic elements are connected or not, or deciding that a 2D drawing is representing a 3D object. Also included is the automatic decision between writing and drawing, that should control the switching between two different modes of the recognizer. We can expect that additional hand-drawing information such as velocity or time course, can assist in this step. Most aspects of this second step are new and remain to be explored (partly within the proposed project).
The last step is the contextual recognition, which is very dependent on the application area of the pen input system. The basic geometrical elements have to be combined into elements that make sense in the given application (for instance, resistors, and transistors in the electronic circuit drawing example). This relates to classical object recognition based on features, and traditional methods, such as statistical classifiers and neural networks, may potentially be used in this step.
The aim of the proposed project is hence to develop a multi-function pen based input system. It is planned to use PenOffice as its handwriting recognition engine. At this moment, we are checking the possibility to use PenOffice inside applications without conflicts. The engine that recognizes the drawings will be developed within the project. A simple command entry mode, supporting selection and drag-and-drop operations, may also be included at a later stage.
We will apply this pen input system as a SPICE preprocessing system. SPICE is a widely used electronic circuit simulation system. SPICE-based simulators work with text format files, containing the information about the structure of the electronic network, its elements and element characteristics and the kind of analysis that has to be performed. Many existing simulators use a schematic editor, which allows to construct a network using libraries of element symbols. After preprocessing, the network information is transferred into a SPICE input file, which the simulator can use to perform the actual network simulation. To the best of our knowledge, a preprocessing system based on free style drawing, connected with SPICE applications, does not exist. The proposed scheme should be compatible with other SPICE applications, so that it can potentially also be used in combination with a schematic editor (for building sub-circuits, new models, etc.).
E3DAD (Easy 3D Architecturall Design)
Jean-Bernard Martens
Currently, pen and paper are still the most frequently used tools in the early, conceptual, stage of architectural design. Advanced computer tools, such as 3D (three-dimensional) visualization, only enter at a later stage when many detailed decisions about the design have already been made. The general aim of the project is to develop computer tools that give improved assistance to the designer in the conceptual design stage. This may not only improve the efficiency of the design itself (because the computer may for instance assist in a better and faster understanding of the implications of alternative design choices), but may also make the transfer to later stages, such as visualization, easier and faster.
The proposed overall project consists of three interrelated PhD projects. The research problem of the first project "A 3D design system for architectural design" (at VR-DIS) is to develop the design theoretical and design system foundation for the overall project. Both existing expertise in the VR-DIS group and active user involvement (for instance, through brainstorm sessions with architects) will serve as input. The existing expertise at VR-DIS has for instance inspired the current focus on geometric modeling, i.e., the idea being that a flexible and intuitive way of creating and modifying 3D forms can assist creativity, because it can support the often observed tendency to play with the shapes of building elements in early design. The possibility of creating 3D forms by moving an elementary building block, such as a cube, through 3D space is currently being explored In the project DDDoolz). The second project "Modeling autonomous simulated devices in virtual environments" (at Computer Graphics) concentrates on specifying and implementing new (autonomous) tools that can assist in creating and modifying 3D forms. The current focus is on deducing 3D form from 2D sketches. The third project "User interfaces for design tools in virtual reality" (at IPO) has a twofold objective: one is to assist in a user-centered design approach towards definining and evaluating the design tool itself, the other is to propose interface solutions that make use of new developments in interface technology. A moderated brainstorm session with architects is currently being prepared, while a prototype of a 2D drawing tool on the existing Visual Interaction Platform (VIP) is under development.
The proposed project is still in an early stage. This means that the design tool to be developed has not been decided on in detail, let alone that choices about the implementation have been made. The application offered by this project is expected to be of interest for other research groups (such as, for instance, for the people working on user-centered design and interface technology, i.e., haptic, speech, sound. handwriting, etc), and a presentation at SUSI is therefore thought to be useful. We are of course interested in comments and references to relevant knowledge.
Publieksreacties op energie-opwekking uit biomassa.
Anneloes Meijnders en Cees Midden
Technologie Management
Abstract
Het doel van dit onderzoek is het vergroten van het inzicht in de attitudes van het algemene publiek ten aanzien van de opwekking van energie uit biomassa. De nadruk ligt hierbij op de structuur (de cognitieve en emotionele aspecten) en de sterkte van deze attitudes. De uitkomsten van dit onderzoek zullen worden vertaald naar implicaties voor het ontwerp van energiesystemen en voor de wijze waarop deze systemen geïmplementeerd worden. Het onderzoek maakt deel uit van een onderzoeksprogramma getiteld 'biomassa als duurzame energiebron: milieubelasting, kosteneffectiviteit en publieksacceptatie'. Bij dit onderzoeksprogramma zijn tevens de faculteiten Scheikundige Technologie en Werktuigbouwkunde betrokken. Het programma wordt gecoördineerd door Centrum Technologie voor Duurzame Ontwikkeling.
Transparent Audio Communication in Offices (TACOs)
Dr.ir P.C.W. Sommen (E), dr.ir. R.N.J. Veldhuis (IPO), prof.dr. A.G. Kohlrausch (IPO).
Primaire doelstelling
Het doel van dit voorstel is het doen van onderzoek aan en het ontwikkelen van een audiocommunicatiesysteem voor kantooromgevingen waarmee personen in hun eigen kantoren met elkaar kunnen spreken alsof ze zich in één ruimte bevinden.
Probleemstelling
In een kantooromgeving kan het wenselijk zijn met één of meer collega's te spreken zonder fysiek samen te komen. Dit is bijvoorbeeld het geval als slechts kort ruggespraak gehouden hoeft te worden, als er geen vergaderruimte beschikbaar is of als de geografische afstand tussen de gesprekspartners zo groot is dat elkaar opzoeken teveel tijd zou kosten. In het project wordt voor die situaties een oplossing gezocht door een systeem te ontwerpen dat in de kamer van elke partner voor elke (afwezige) spreker een realiseert. Deze bronnen kunnen dan in een conversatie geadresseerd worden alsof de afwezige spreker wel in de ruimte aanwezig is. In dit project wordt er bovendien naar gestreefd de gebruiker een zo groot mogelijke bewegingsvrijheid in zijn eigen ruimte te geven.
Een eerste probleem dat hierbij opgelost dient te worden is de realisatie van transparante audiocommunicatie. Speciaal hiervoor moeten signaalbewerkingsalgoritmen ontwikkeld worden voor de onderdrukking van akoestische echo's , achtergrondruis, ongewenste signalen en nagalm. Dit aspect is geen onderdeel van TACOs, maar wordt uitgewerkt in een project Transparante Audio Communicatie (TAC) dat door Sommen bij STW is aangevraagd. TACOs zal gebruikmaken van de resultaten die in de loop van dit STW-project beschikbaar komen en deze integreren in een systeem voor kantoortoepassing.
Een tweede probleem, dat wèl in TACOs geadresseerd moet worden, is de realisatie met een beperkt aantal vaste luidsprekers van een nauwkeurig gelokaliseerde virtuele geluidsbron voor elke spreker in een zogenaamd auditory display. Een randvoorwaarde hierbij is dat deze lokalisatie door de gebruiker ingesteld moet kunnen worden.
Een derde probleem is de bediening van het te ontwikkelen audiocommunicatiesysteem voor een kantooromgeving. Aspecten hiervan zijn:
In TACOs worden de mogelijkheden onderzocht van een bediening gebaseerd op een zogenaamde Personal Communication Assistant (PCA), die met spraak communiceert met de gebruiker. Deze PCA is een spraakinterface ingebouwd in, bijvoorbeeld, een poppetje dat staat op het bureau van elke gebruiker. Een probleem bij spraakbediening van een communicatiesysteem voor spraak is de mogelijke verwarring van communicatieboodschappen en bedieningscommando's. Een oplossing is de commando's vooraf te laten gaan door een commandowoord, bijvoorbeeld de naam van de PCA. Eleganter en betrouwbaarder lijkt het om dit te combineren met het detecteren van de kijkrichting van de gebruiker, zodat commando's alleen worden geaccepteerd als de gebruiker de PCA aankijkt. Dit kan betekenen dat gedurende de bediening van het systeem de gebruiker minder bewegingsvrijheid heeft omdat hij goed zichbaar moet zijn voor de PCA. Hoe groot deze beperking zal zijn, hangt van de uitvoering van de PCA af. Voor de communicatie geldt de beperking niet. De functionaliteit van de PCA kan in een vervolgproject worden uitgebreid met bijvoorbeeld agendabeheer, beheer van adressenbestanden en ondersteuning bij computergebruik zodat de PCA uitgroeit tot een desktop Personal Digital Assistant (PDA).
TACOs is dus de combinatie van een transparant audiocommunicatiesysteem met een PCA voor kantoortoepassingen. Het project valt uiteen in de vier volgende onderdelen:
Aanpak
Het te realiseren systeem wordt ontwikkeld voor gebruik op één locatie. Daardoor kan worden gewerkt met niet-draadloze verbindingen. Onderzocht moet worden of een bestaand computernetwerk gebruikt kan worden voor de communicatie. Dit gebeurt in een definitiefase, waarin eveneens de initiële specificaties van het systeem worden vastgesteld. Deze zijn: het maximum aantal gebruikers, de toegelaten mobiliteit van een gebruiker in zijn kamer, de commando's voor de PCA, de gesproken output van de PCA. Hiertoe kan, zonder dat er een transparant audiocommunicatiesysteem beschikbaar is, gewerkt worden met mock ups en Wizard-of-Oz experimenten. De aanpak is vervolgens concentrisch. Regelmatig worden prototypes ontwikkeld en geëvalueerd. De resultaten bepalen dan het volgende prototype. Het eerste prototype is de mock up uit de definitiefase. Verder wordt ernaar gestreefd om tenminste elk jaar een demonstreerbaar prototype af te leveren. Het totale project heeft een looptijd van 4 jaar. De uitvoering geschiedt in vier deelprojecten:
Voorgesteld wordt verder om zowel bij de faculteit Elektrotechniek als bij het IPO een projectleider te benoemen. Bij Elektrotechniek zou dat Sommen zijn, bij het IPO Veldhuis.
Inzet
Hieronder wordt een eerste schatting gegeven voor de personele inzet voor TACOs. Er wordt geen uitspraak gedaan over de beschikbaarheid en inzetbaarheid van vaste staf voor de uitvoering van de deelprojecten, omdat dit een zaak is van het management van Elektrotechniek en het IPO.
Deelprojecten 1, 3 en 4 vragen gedurende 4 jaar de inzet van elk 1 FTE. Deelproject 2 vraagt gedurende 2 jaar de inzet van 1 FTE. Verder is er gedurende 4 jaar behoefte aan technische ondersteuning, een eerste schatting hiervan is 0.5 FTE. De invulling van deelprojecten 1, 3 en 4 kan zowel gedaan worden door de vaste staf als met AIO's of postdocs. In het geval van invulling met AIO's en postdocs moet er vanuit de vaste staf per AIO of postdoc nog 0.1 FTE begeleidingscapaciteit worden gereserveerd. Deelproject 2 moet worden ingevuld door de vaste staf of door een ervaren postdoc. Voor het projectleiderschap moet per projectleider ook nog 0.1 FTE worden gereserveerd.
In totaal betekent dit een inzet van minimaal 16.8 en maximaal 18.2 mensjaar. Naast deze inzet van personeel, is er ook nog een te specificeren apparatuurbudget.
COMRIS: COhabited Mixed Reality Information Spaces (ESPRIT -25500)
Jacques Terken
IPO
Aim
COMRIS is about providing relevant information to members of a community. The selection of the information is taken care of by a set of intelligent, autonomous agents that stroll the information space looking for information that matches the current interests of a particular member. The information in the space is provided by agents representing the interests of other members. Thus, the communication between the agents representing the interests of different members of the community involves a negotiation and selection process.
The connection between the information space and the physical space is established by means of wearable devices ("parrots"), which push relevant messages onto their owners by means of spoken messages. Thus, the COMRIS project focuses on the coupling of virtual and physical space (co-habited mixed-reality information spaces). However, the project does not pursue the perceptual integration of real and virtual space into an augmented reality. Instead, the coupling aims at focusing the large potential for useful social interactions in each of the spaces, so that they become more manageable, goal-directed and effective.
Relevance
The project brings together ideas from different backgrounds (software agents, virtuality, networking, robotics, machine learning, social science) into a coherent concept and technical approach towards intelligent information interfaces.
Background
The COMRIS project uses the conference center as the thematic space and concrete context of work. At a conference, like the Annual Esprit meeting in Brussels, people gather to show their results, see other interesting things, find interesting people, meet EU officials in person, or engage in any kind of discussion. The possibilities of interaction at such an event are enormous, it is very information-intensive, and the great diversity of topics and purposes that are being addressed make it difficult to get everything done. This clearly motivates our aim to enhance the effectiveness of participation to such or another large event.
In the mixed-reality conference center real and virtual conference activities are going on in parallel. Each participant wears its personal assistant, wirelessly hooked into an Intranet. This personal assistant - the COMRIS parrot - realizes a bidirectional link between the real and virtual spaces. It observes what is going on around its host (whereabouts, activities, other people around), and it informs its host about potentially useful encounters, ongoing demonstrations that may be worthwhile attending, and so on. This information is gathered by several personal representatives, the software agents that participate on behalf of a real person in the virtual conference. Each of these has the purpose to represent, defend and further a particular interest or objective of the real participant, including those interests that this participant is not explicitly attending to.
Research Questions
The COMRIS project aims to develop, demonstrate and experimentally evaluate a scalable approach to integrating the Inhabited Information Spaces schema with a concept of software agents. Hardware challenges (e.g. the parrot on wireless Intranet) are complemented with software challenges and usability issues:
Project Description
Two major milestones, in which feasibility is demonstrated, are complemented with a series of concrete and rigorous experiments, in which the scaling properties are investigated. After two iterations, in which the COMRIS vision and demonstration objectives are gradually extended, the project will have achieved an integrated package of results, accompanied by a series of recommendations for post-project extension, technical implementation, and exploitation.
Keywords
Intelligent Information Interfaces; Wearables; Context-sensitive information filtering; Speech Interface
An Information retrieval agent for written and spoken documents
Jacques Terken
IPO
Aim
To develop an Information Retrieval agent which digests text and speech documents and informs the user about relevant contents in a way which is appropriate to the current needs of the user.
The agent takes initiative in searching for relevant documents and presents automatically derived summaries to the user.
Relevance
Having the right (i.e., relevant and up-to-date) information available at the right time becomes an ever more important determinant of high level business and academic activities. The current project contributes to the retrieval technology that is needed to meet the information needs of workers in business and academic environments.
Background
A lot of work is already being done on Information retrieval. So far, it concerns mainly text documents (although work is going on concerning the retrieval of spoken documents as well) and it is mainly a user-driven process (although there is work going on concerning agent-driven systems as well). Finally, the outcome of the information retrieval process mostly consists of one or more documents meeting the search criteria of the user, without further processing the information in order support the information processing by the user (although there is work going on in the area of automatic summarization). Particular topics where Eindhoven University of technology might contribute are agent technology for filtering and automatic summarization, in particular from spoken documents.
Research Questions
The research focuses on the following topics:
Keywords
Information retrieval; spoken document retrieval; information filtering; automatic summarization
The MARVIN janitor
Jacques Terken
IPO
AimThe project aims to investigate issues related to the application of speech technology in the context of mobile technology, using a toy robot as the experimentation and demonstration platform. The toy robot will perform janitor functions in IPO.
RelevanceMobile technology will provide the user with access to functionality not constrained by his/her physical whereabouts. This creates the possibility to provide the user with information whenever suitable, depending on the situation and the user's interests and context. Key issues are the robustness of the context identification (both physical and social) and the notion of relevance. Another key issue concerns the usability of speech technology in the context of mobile devices. Exploring the technological issues will contribute to tuning the technology to the needs of the users.
Background
Two students of the SAI course User-System Interaction course 1998-1999 have developed a robot, MARVIN, using Lego Mindstorms (http://www.legomindstorms.com/), to explore hardware and software issues in interaction technology (http://www.bartneck.de/marvin/index.html). This provides a neat point of departure and platform for further and more structured exploration of interaction concepts involving mobile assistants. In particular, it provides a way to build our own institutional environment into a test site for interaction technology.
In order to explore the MARVIN concept further, the current proposal aims to develop a demonstrator of a mobile assistant who can perform janitor functions in IPO. Some of the tasks of the janitor might be to welcome people, help them find their way, localize people in a crowd to deliver messages, for instance during receptions in the central hall of IPO. In order to do this, people in the crowd might be equipped with badges that enable the robot to localize them.
Research Questions
The concept of mobile assistants raises a number of issues and technological challenges.
Mobile assistants should be able to orient themselves in space. Furthermore, janitor functions call for perceptual and action capabilities, and (limited) natural language capabilities. Some of these capabilities need to run on servers.
Thus, technological challenges concern among others the following:
To some extent, the technology is already available, so part of the challenge is in combining existing technologies in the context of a mobile system.
Keywords
Wireless communication; speech technology
MATIS: Multimodal Transaction and Information Services (IOP-MMI)
Raymond Veldhuis and Jacques Terken
IPO
Aim
The aim of this project is to investigate how speech and graphics (text as well as 2D or 3D graphics) can be combined to improve the user interface for information and transaction services.
Relevance
Speech and graphics are in particular suited for situations where keyboard and mouse input is not feasible and users can only dispose of a display with limited resolution, e.g. handheld devices, GSM, mobile computing, web phones, set-up boxes. MATIS will generate knowledge about how speech and visual information can be integrated in user interfaces for information and transaction services and how this affects the behaviour of users. The project will generate improved technology for automatic speech recognition, dialogue models for multi-modal interaction, methods for adaptive visual presentation, and techniques for reasoning about graphic representations. The project will built several prototypes and will test these in real services for real customers. The MATIS project aims to develop and integrate the different modalities in one framework and to make this framework readily available for the dutch industry.
Background
The growing amount of mobile and handheld devices without an extended keyboard or mouse (GSM, PDA, etc.) but with a limited graphics display has increased the interest in multi-modal interaction using a combination of speech and graphics. Communication protocols have been developed to provide standard interfaces to information and transaction services using portable and handheld devices with a limited display functionality such as screen phones. One such protocol is HDML (Hand-held Device Mark-up Language), derived from HTML, and explicitly meant to make internet-services available to mobile users. Multi-modal interfaces may provide a flexible and user friendly interface for these mobile informaton services.
Next to devices with limited display functionality, there is also a growing amount of devices with more extended graphics functionality such as tv set-up boxes, remote controls for video displays, and portable and/or wireless mobile computers. The more powerful graphics of these devices allows a better presentation and interaction with the application than with text displays only. Tele-shopping, and route planning are typical applications that make use of these more advanced display functionalities.
Research Questions
A key feature for the success of multi-modal interfaces is the optimal combination of speech and graphics. So far, there has not been much experience with the integration of different input media and with the choice of optimal output media as a function of the developing dialogue. It may be expected that both the speech recognition and the dialogue management will have to be adjusted to support a fluent dialogue. The presence of visual feedback will allow the user to directly interact with the dialogue manager about the results of the speech recognition, in particular in case of confusion and misunderstanding. This will eliminate tedious verification strategies. However, this will also require that the visual feedback should be synchronous with the dialogue, i.e. the speech recognizer should not wait till the end of an utterance but as soon as a meaningful sub-item has been recognized, it will be directly transferred to the dialogue manager ('early decision'). The dialogue manager should also be able to directly respond to interrupts of the user.
The growing complexity of services and appliances will require more intelligent and flexible dialogues. It is not acceptable to ask users to enter predefined commands and sentences. For novice users this is even impossible. Users should be able to enter information in a less-structured way and be able to use for instance referential expressions such as the 'previous one' or the 'left one'. Dialogue managers should be cooperative in the sense that they will anticipate the user's intentions and can propose suggestions and alternatives in case of confusion or misunderstanding. For these more 'free' dialogue structures, the additional graphics feedback may help to structure the dialogue and provide the user with sufficient context.
Further, for graphics applications in particular, the dialogue should enable the users to refer to graphic objects and the dialogue manager will have to understand the relation between the spoken dialogue and the visual presentation. Moreover, the visual information may change dynamically due to changes of viewpoint, 'pan-and-zoom' and different levels-of-detail. The dialogue manager should therefore have knowledge about the graphics representation and should be able to reason about it. So far there are not many systems that can handle this type of interaction. One notable exception is the dialogue manager developed in the DenK-project.
Project Description
The project will develop dialogue models for multi-modal communication and will study the impact of visual presentation and feedback on speech recognition and on dialogue management. The project will implement the developed dialogue models in experimental systems using existing speech and graphics technology and will evaluate these using realistic user tests.
Main Activities
Two applications will be developed:
By concentrating the research on speech recognition and dialogue management in application (A), and graphics interaction and dialogue management in application (B), the project will be able to develop both lines of research without a too strong mutual interdependence. However, the two projects will use the same basic architecture and at the end of the project the two lines of research will be integrated.
Keywords: Multi-modale interfaces, speech recognition, dialogue management, visual presentation, information- en transaction services
Vertrouwen en controle in geautomatiseerde informatieoverdracht
M. Willemsen en G. Keren
Technology Management
Samenvatting
Het eerste doel van het project is om de interactie te bestuderen tussen gebruikers en geautomatiseerde informatiesystemen en via een reeks van experimenten inzicht te verwerven in het effect van vertrouwen in het systeem op de allocatie van controle aan systeem of gebruiker. Het daaraan gekoppelde doel is het vergaren van fundamentele kennis over hoe schermgebaseerde informatie weergegeven en gepresenteerd moet worden. Deze kennis wordt van steeds groter belang door de ontwikkelingen die er zijn binnen informatiemedia. Tenslotte is er het doel om inzicht te verwerven in factoren die aan het ontstaan en instandhouden van vertrouwen ten grondslag liggen. Er wordt verwacht op grond van het voorgestelde onderzoek te komen tot richtlijnen voor het ontwerp van geautomatiseerde informatiesystemen. Dit geldt voor het ontwerp van de interactiestijl van het systeem of de applicatie, en voor de wijze waarop productinformatie het beste kan worden weergegeven.
Tot nu toe is er, ondanks de goede vorderingen in de besliskunde, weinig geprobeerd haar resultaten toe te passen in technologische ontwerpen. Ook wetenschappelijk onderbouwde onderzoeken op het gebied van informatiepresentatie en geloofwaardigheid zijn schaars. Voorts blijkt bij de voortdurende opmars van automatische informatie- en transactiesystemen dat het vertrouwen van de gebruiker in het systeem een kritische variabele is voor acceptatie.
In twee deelprojecten wordt deze problematiek onderzocht. In het eerste deelproject wordt de mate van control van de gebruiker over het informatiesysteem systematisch gevarieerd, waarbij zaken als kennis, achtergrondinformatie, directe en indirecte ervaring worden gemanipuleerd. In het tweede deelproject wordt zowel de vorm van de informatie als de bron van de informatie (b.v. persoon of informatieautomaat) systematisch gevarieerd. Vertrouwen wordt indirect gemeten door keuzegedrag en door maten van subjectieve onzekerheid, en meer direct door rechtstreeks ernaar te vragen via directe vergelijking of met rating scales.